ShockHash


A minimal perfect hash function (MPHF) maps a set S of n keys to the first n integers without collisions.
Perfect hash functions have applications in databases, bioinformatics, and as a building block of various space-efficient data structures.
ShockHash (small, heavily overloaded cuckoo hash tables) is an MPHF that achieves space very close to the lower bound,
while still being fast to construct.
In contrast to the simple brute-force approach that needs to try e^n = 2.72^n different hash function seeds,
ShockHash significantly reduces the search space.
Instead of sampling hash functions hoping for them to be minimal perfect, it samples random graphs,
hoping for them to be a pseudoforest.
In its most space-efficient variant, it can reduce the running time to just 1.16^n,
while still being asymptotically space optimal.
Still being an exponential time algorithm, we integrate ShockHash into several partitioning frameworks.
Our implementation inside the RecSplit framework achieves the best space efficiency.
Using ShockHash inside our novel k-perfect hash function achieves fast queries
while still being faster to construct and more space efficient than any previous approaches.
Library Usage
Clone this repo and add the following to your CMakeLists.txt.
Note that the repo has submodules, so either use git clone --recursive or git submodule update --init --recursive.
add_subdirectory(path/to/ShockHash)
target_link_libraries(YourTarget PRIVATE ShockHash)
Then use one of the following classes:
- ShockHash is the original ShockHash algorithm integrated into the RecSplit framework.
- SIMDShockHash is the SIMD-parallel version of the original ShockHash algorithm. Both ShockHash and the RecSplit framework are SIMD-parallelized. If this implementation is used on a machine without SIMD support, it is slower than the non-SIMD version because SIMD operations are emulated.
- ShockHash2 is the bipartite ShockHash algorithm. Only the inner ShockHash loop is SIMD-parallel, the RecSplit framework is not. If this implementation is used on a machine without SIMD support, the implementation uses sequential operations without explicitly emulating SIMD. To turn off SIMD, change to SIMD lanes of size 1 in ShockHash2-internal.h.
Constructing a ShockHash perfect hash function is then straightforward:
std::vector<std::string> keys = {"abc", "def", "123", "456"};
shockhash::ShockHash<30, false> shockHash(keys, 2000); // ShockHash base case size n=30, bucket size b=2000
std::cout << shockHash("abc") << " " << shockHash("def") << " "
<< shockHash("123") << " " << shockHash("456") << std::endl;
// Output: 1 3 2 0
We also give the base-case implementations without the RecSplit framework, which makes it easier to understand the main idea.
- Original ShockHash.
- Bipartite ShockHash. The outer loop that is also given in the pseudocode of the paper is given in
BijectionsShockHash2::findSeed.
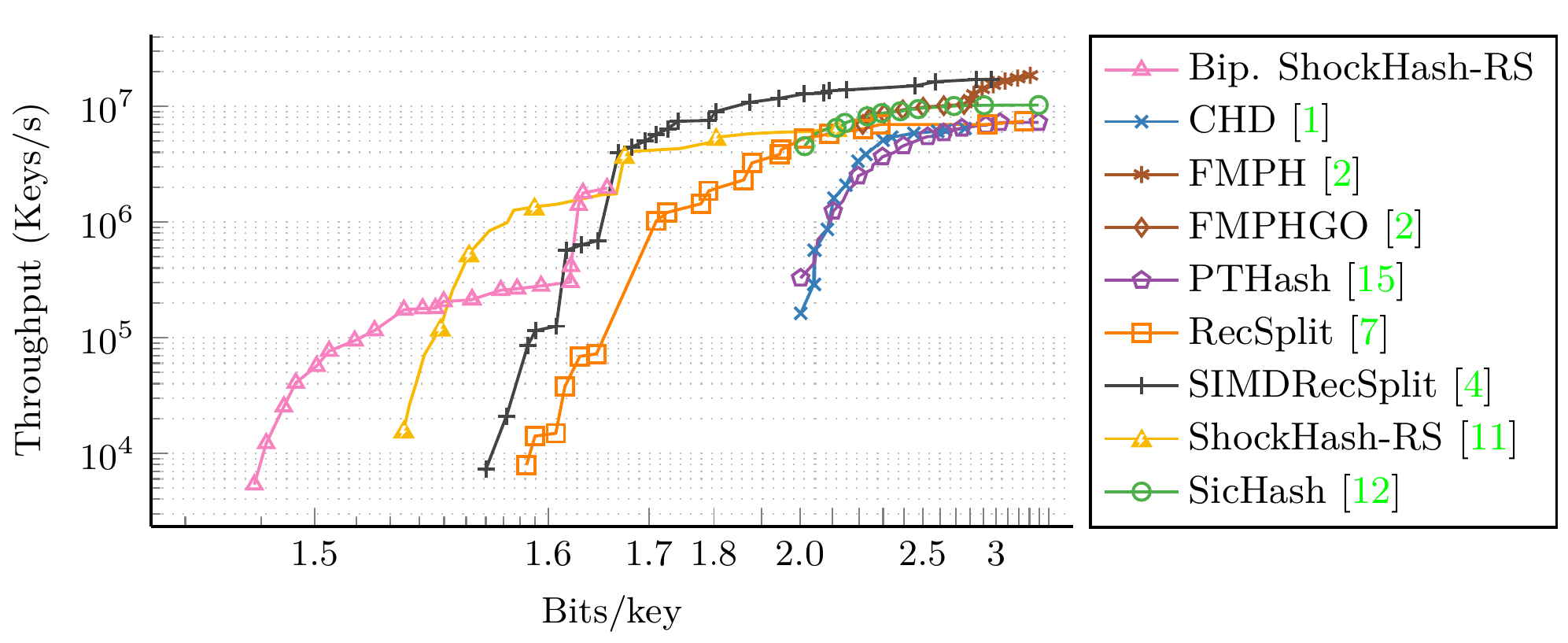
Construction performance
Licensing
ShockHash is licensed exactly like libstdc++ (GPLv3 + GCC Runtime Library Exception), which essentially means you can use it everywhere, exactly like libstdc++.
You can find details in the COPYING and COPYING.RUNTIME files.
If you use ShockHash or bipartite ShockHash in an academic context or publication, please cite our papers:
@inproceedings{lehmann2023shockhash,
author = {Hans-Peter Lehmann and
Peter Sanders and
Stefan Walzer},
title = {{ShockHash}: Towards Optimal-Space Minimal Perfect Hashing Beyond Brute-Force},
booktitle = {{ALENEX}},
pages = {194--206},
publisher = {{SIAM}},
year = {2024},
doi = {10.1137/1.9781611977929.15}
}
@article{lehmann2023towardsArxiv,
author = {Hans-Peter Lehmann and
Peter Sanders and
Stefan Walzer},
title = {{ShockHash}: Towards Optimal-Space Minimal Perfect Hashing Beyond Brute-Force},
journal = {CoRR},
volume = {abs/2308.09561},
year = {2023},
doi = {10.48550/ARXIV.2308.09561}
}