Get started
1368 commitsLast commit ≈ 12 months ago24 stars8 forks
A Python library and command line application to download, process and visualize event-based seismic waveform segments, specifically designed to manage big volumes of data
| Jump to: | Usage | Installation | Development and Maintenance | Citation |
|---|
A Python library and command line application to download, process and visualize event-based seismic waveform segments, specifically designed to manage big volumes of data.
The key aspects with respect to widely-used similar applications is the use of a Relational database management system (RDBMS) to store downloaded data and metadata. The main advantages of this approach are:
Storage efficiency: no huge amount of files, no complex, virtually unusable directory structures. Moreover, a database prevents data and metadata inconsistency by design, and allows more easily to track what has already been downloaded in order to customize and improve further downloads
Simple Python objects representing stored data and relationships, easy
to work with in any kind of custom code accessing the database. For instance, a
segment is represented by a Segment object with its data, metadata and related
objects easily accessible through its attributes, e.g., segment.stream(),
segment.maxgap_numsamples, segment.event.magnitude,
segment.station.network, segment.channel.orientation_code and so on.
A powerful segments selection made even easier by means of a simplified
syntax: map any attribute described above to a selection expression
(e.g. segment.event.magnitude: "[4, 5)") and with few lines you can compose
complex database queries such as e.g., "get all downloaded segments within a
given magnitude range, with well-formed data and no gaps,
from broadband channels only and a given specific network"
For full details, please consult the wiki page
Stream2segment is a Python library and command line application available
after installation via the command s2s on the terminal. By typing s2s --help you
will see all available subcommands for downloading
and managing data, launching Python processing functions, creating class labels for segments
annotation, or producing graphical output, as shown below:
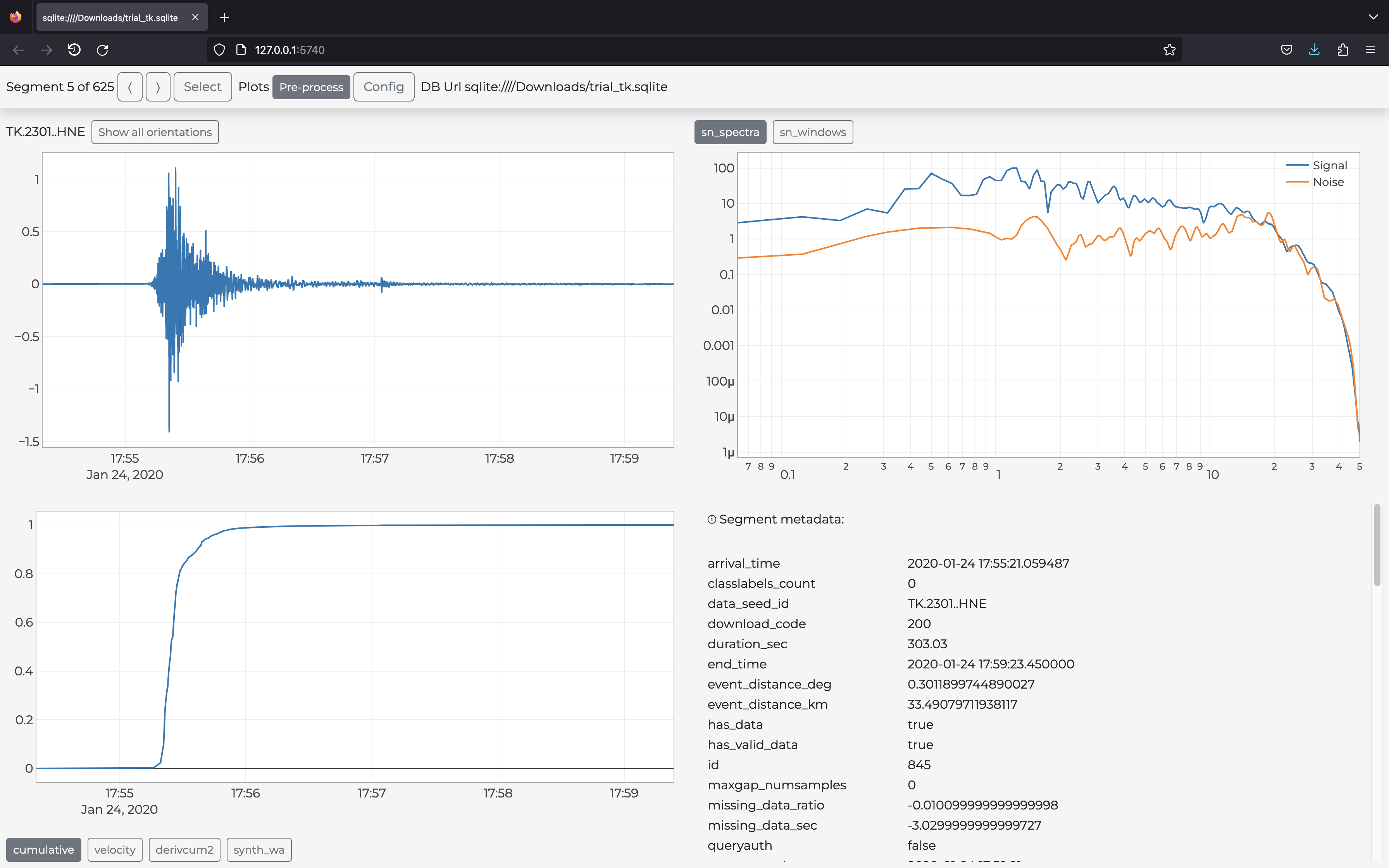
You start the program via the command init (
s2s init --help for details) to create several fully documented
examples files that you can immediately start to configure and modify
(see the gitHub wiki page for details).
In a nutshell:
A download configuration file in YAML syntax. Edit the file (all documentation is provided in the file as block comments) and start downloading by typing:
s2s download -c <config_file> ...
Note the path of the database where to store the downloaded data must be input in the config file. The supported database types are SQLite and Postgres: for massive downloads (as a rule of thumb: ≥ 1 million segments) we suggest to use Postgres. In any case, we strongly suggest running the program on computers with at least 16GB of RAM.
Note massive downloads are time-consuming operations where it is likely to miss some data due to any kind of temporary connection problems. Consequently, it is advisable to perform the same massive download at least twice with the same configuration
(subsequent runs will be faster as data will not be re-downloaded unnecessarily)
A Jupyter notebook tutorial with examples for processing downloaded data, for user who prefer this approach instead of the processing module described below (online version here)
Two Python modules (with relative configuration in YAML syntax):
paramtable.py: process downloaded data and produce a tabular output (CSV, HDF) by executing the
module as script (see code block after if __name__ == "__main__" in the module for details):
python paramtable.py ...
gui.py: visualize downloaded data in the user browser via the plots defined in the module (an example in the figure above):
s2s show -d download.yaml -p gui.py -c gui.yaml ...
(Type s2s show --help for details).
Note: the associated YAML files (
paramtable.yaml,gui.yaml) are not mandatory but enforce the good practice of separating configuration settings (YAML) and the actual Python code. This way you can experiment the same code with several settings by only creating different YAML files
This program has been installed and tested on Ubuntu (14 and later) and macOS (El Capitan and later).
In case of installation problems, we suggest you to proceed in this order:
In this section we assume that you already have Python (3.5 or later) and the required database software. The latter should not be needed if you use SQLite or if the database is already installed remotely, so basically you are concerned only if you need to download data locally (on your computer) on a Postgres database.
On macOS (El Capitan and later) all required software is generally already preinstalled. We suggest you to go to the next step and look at the Installation Notes in case of problems (to install software on macOS, we recommend to use brew).
In few cases, on some computers we needed to run one or more of the following commands (it's up to you to run them now or later, only those really needed):
xcode-select --install
brew install openssl
brew install c-blosc
brew install git
Ubuntu does not generally have all required packages pre-installed. The bare minimum
of the necessary packages can be installed with the apt-get command:
sudo apt-get install git python3-pip python3-dev # python 3
In few cases, on some computers we needed to run one or more of the following commands (it's up to you to run them now or later, only those really needed):
Upgrade gcc first:
sudo apt-get update
sudo apt-get upgrade gcc
Then:
sudo apt-get update
sudo apt-get install libpng-dev libfreetype6-dev \
build-essential gfortran libatlas-base-dev libxml2-dev libxslt-dev python-tk
Git-clone (basically: download) this repository to a specific folder of your choice:
git clone https://github.com/rizac/stream2segment.git ./stream2segment
and move into the repository root:
cd stream2segment
We strongly recommend to use Python virtual environment to avoid conflicts with already installed packages on your operating system (if you already have a virtual environment, just activate it and go to the next section).
Conda users (e.g. Anaconda, Miniconda) can skip this section and check the Conda documentation instead.
Make virtual environment in a "stream2segment/env" directory (env is a convention,
but it's ignored by git commit so better keeping it. You can also use ".env"
which makes it usually hidden in Ubuntu. Also on Ubuntu, you might need to install
venv first via sudo apt-get install python3-venv)
python3 -m venv ./env
To activate your virtual environment, type:
source env/bin/activate
or source env/bin/activate.csh (depending on your shell)
Activation needs to be done each time we will run the program. To check you are in the right env, type:
which pipand you should see it's pointing inside the env folder
Important reminders before installing:
Install the required packages with the tested versions listed in requirements.txt
(if you are working on an existing environment with stuff
already installed in it, please read the first installation note below
before proceeding):
pip install --upgrade pip setuptools wheel && pip install -r ./requirements.txt
type
requirements.dev.txtinstead ofrequirements.txtif you want to install also test packages, e.g., you want to contribute to the code and/or run tests
Install this package:
pip install -e .
(optional) install jupyter notebook or jupyterlab (see Jupyter page for details), e.g.:
pip install jupyterlab
The program is now installed. To double-check the program functionalities, you can run tests (see below) and report the problem in case of failure. In any case, before reporting a problem remember to check first the Installation Notes
in case of a message like ERROR: No matching distribution found for <package_name>,
try to skip the requirements file:
pip install --upgrade pip setuptools wheel && pip install -e .
This will install packages satisfying a minimum required
version instead of the exact version passing tests: while less safe in general, this approach
lets pip handle the best versions to use, with more chance of
success in this case. You can choose this strategy not only in case of mismatching distributions,
but also while working on a virtual environment with already installed packages,
because it has less chance of breaking existing code.
In older ObsPy version, numpy needs to be installed first. If you see an error
like "you need to install numpy first", open "requirements.txt" and copy the
line which starts with numpy. Supposing it's numpy==0.1.12, then run
pip install numpy==0.1.12 before re-running the pip install ... command
above
When installing the program (pip install -e .), -e is optional and
makes the package editable, meaning that you can edit the repository and make all
changes immediately available, without re-installing the package. This is useful
when, e.g., git pull-ing new versions frequently.
(update January 2021) On macOS (version 11.1, with Python 3.8 and 3.9):
If you see (we experienced this while running tests, thus we can guess you should see it whenever accessing the program for the first time):
This system supports the C.UTF-8 locale which is recommended.
You might be able to resolve your issue by exporting the
following environment variables:
export LC_ALL=C.UTF-8
export LANG=C.UTF-8
Then edit your ~/.profile (or ~/.bash_profile on Mac) and put the two lines starting
with 'export', and execute source ~/.profile (source ~/.bash_profile on Mac) and
re-execute the program.
On Ubuntu 12.10, there might be problems with libxml (version libxml2_2.9.0' not found).
Move the file or create a link in the proper folder. The problem has been solved looking
at http://phersung.blogspot.de/2013/06/how-to-compile-libxml2-for-lxml-python.html
All following issues should be solved by installing all dependencies as described in the section Prerequisites. If you did not install them, here the solutions to common problems you might have and that we collected from several Ubuntu installations:
For numpy installation problems (such as Cannot compile 'Python.h') , the fix
has been to update gcc and install python3-dev (python2.7-dev if you are using Python2.7,
discouraged):
sudo apt-get update
sudo apt-get upgrade gcc
sudo apt-get install python3-dev
For details see here
For scipy problems, build-essential gfortran libatlas-base-dev are required for scipy.
For details see here
For lxml problems, libxml2-dev libxslt-dev are required. For details see here
For matplotlib problems (matplotlib is not used by the program but from imported libraries),
libpng-dev libfreetype6-dev are required. For details see
here and
here
Stream2segment has been highly tested (current test coverage is above 90%) on Python version >= 3.5+. Although automatic continuous integration (CI) systems are not in place, we do our best to regularly tests under new Python and package versions. Remember that tests are time-consuming (some minutes currently). Here some examples depending on your needs:
pytest -xvvv -W ignore ./tests/
pytest -xvvv -W ignore --dburl postgresql://<user>:<password>@localhost/<dbname> ./tests/
pytest -xvvv -W ignore --dburl postgresql://<user>:<password>@localhost/<dbname> --cov=./stream2segment --cov-report=html ./tests/
Where the options denote:
-x: stop at first error-vvv: increase verbosity,-W ignore: do not print Python warnings issued during tests. You can omit the -W
option to turn warnings on and inspect them, but consider that a lot of redundant
messages will be printed: in case of test failure, it is hard to spot the relevant error
message. Alternatively, try -W once - warn once per process - and -W module -warn
once per calling module.--cov: track code coverage, to know how much code has been executed during tests, and
--cov-report: type of report (if html, you will have to opened 'index.html' in the
project directory 'htmlcov')--dburl: Additional database to use.
The default database is an in-memory sqlite database (e.g., no file will be created),
thus this option is basically for testing the program also on postgres. In the example,
the postgres is installed locally (localhost) but it does not need to.
Remember that a database with name <dbname> must be created first in postgres, and
that the data in any given postgres database will be overwritten if not emptyNote on coding: although PEP8 recommends 79 character length, the program used initially a 100 characters max line width, which is being reverted to 79 (you might see mixed lengths in the modules). It seems that among new features planned for Python 4 there is an increment to 89.5 characters. If true, we might stick to that in the future
In the absence of Continuous Integration in place, from times to times, it is necessary
to update the dependencies, to make pip install more likely to work (at least for
some time). The procedure is:
pip install -e .
pip freeze > ./requirements.tmp
pip install -e ".[dev]"
pip freeze > ./requirements.dev.tmp
Remember to comment the line of stream2segment
from all requirements (as it should be installed as argument of pip:
pip install <options> ., and not inside the requirements file).
Run tests (see above) with warnings on: fix what might go wrong, and eventually you can
replace the old requirements.txt and requirements.dev.txt with the .tmp file
created.
Requirements (to be done once):
jupyter installed.stream2segment.wiki which you can clone from the
stream2segment/wiki URL on the GitHub page. The repository must
be cloned next to (on the same parent directory of) the
stream2segment repositoryThe wiki is simply a git project composed of Markdown (.md) files, where
Home.md implements the landing page of the wiki on the browser, and thus
usually hosts the table of contents with links to other markdown files .md
in the directory. Currently, two of those .md files are generated from the
notebooks .ipynb inside stream2segment:
Edit the notebook in stream2segment/resources/templates:
jupyter notebook stream2segment/resources/templates
Execute the whole notebook to update it, then git push as usual
Create .md versions of the notebook for the wiki. From the stream2segment
repository as cwd:
F='Using-Stream2segment-in-your-Python-code';jupyter nbconvert --to markdown ./stream2segment/resources/templates/$F.ipynb --output-dir ../stream2segment.wiki
(repeat for every notebook file, e.g. The-Segment-object. Note only the file name,
no file extension needed)
Commit and push to the stream2segment.wiki repo:
cd ../stream2segment.wiki, then as usual git commit and git push. One line command:
(cd ../stream2segment.wiki && git commit -am 'updating wiki' && git push)
Create the notebook (jupyter notebook stream2segment/resources/templates).
Choose a meaningful file name: use upper case when needed, type hyphens '-'
instead of spaces: the file name will be used as title to show the page
online (replacing hyphens with spaces).
Once the notebook is created and executed:
(optional) If you want to include the notebook also as example in the s2s init command,
look at stream2segment/cli.py
Make the notebook being executed during tests (see examples in tests/misc/test_notebook.py)
and run tests to check everything works.
Make the notebook visible in the wiki by adding a reference to it (the notebook URL is the file name with no extension, I guess case- insensitive). A reference can be added in several places:
_Sidebar.md (in the wiki repository)
which will show it in the sidebar on GitHubHome.mdUsing-stream2segment-in-you-Python-code.ipynb). In this case, note that
you might need to update also the referencing notebook
(see points 2-3 above)Create the markdown file and commit to the wiki (see points 2-3 above under
To update one of those existing notebooks)
Software:
Zaccarelli, Riccardo (2018): Stream2segment: a tool to download, process and visualize event-based seismic waveform data. GFZ Data Services. http://doi.org/10.5880/GFZ.2.4.2019.002
Research article:
Riccardo Zaccarelli, Dino Bindi, Angelo Strollo, Javier Quinteros and Fabrice Cotton. Stream2segment: An Open‐Source Tool for Downloading, Processing, and Visualizing Massive Event‐Based Seismic Waveform Datasets. Seismological Research Letters (2019). https://doi.org/10.1785/0220180314