21 commitsLast commit ≈ 3 days ago245 stars26 forks
VoxTell
VoxTell is a vision–language model for text-driven 3D medical image segmentation, enabling analysis of anatomical structures and pathologies across CT, MRI, and PET, including open-set and clinically described targets beyond predefined label sets.
Description
VoxTell: Free-Text Promptable Universal 3D Medical Image Segmentation
![]() ;
;![]()
![]()

VoxTell is a 3D vision–language segmentation model that maps free-form text prompts, from single words to full clinical sentences, to volumetric masks. Through multi-stage vision-language fusion, it achieves state-of-the-art performance on anatomical and pathological structures across CT, PET, and MRI modalities, while generalizing to related unseen classes.
VoxTell is developed by the Division of Medical Image Computing at the German Cancer Research Center (DKFZ) Heidelberg. Code and model weights are openly available on GitHub and Hugging Face, and VoxTell can be installed via PyPI. A napari plugin is provided for interactive use. Community-contributed integrations exist for 3D Slicer, a web-based viewer, and OHIF.
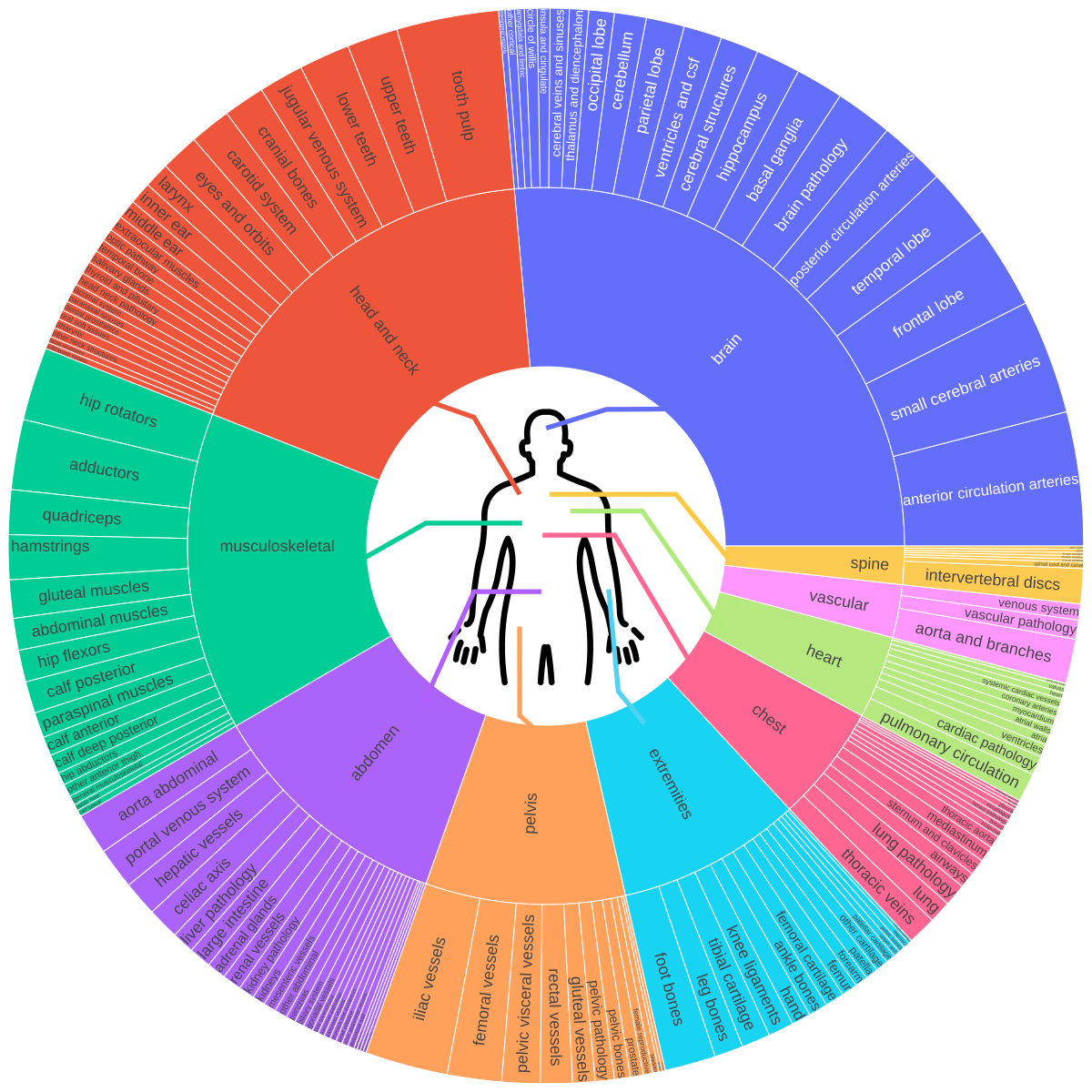
The model is trained on a large-scale, multi-modality 3D medical imaging dataset aggregating 158 public sources with over 62,000 volumetric images, covering brain, head & neck, thorax, abdomen, pelvis, musculoskeletal system, vascular structures, major organs, substructures, and lesions. This semantic diversity enables language-conditioned 3D reasoning, allowing VoxTell to generate volumetric masks from flexible textual descriptions ranging from coarse anatomical labels to fine-grained pathological findings.

License
Packages
Participating organisations
Helmholtz Program-oriented Funding IV
Research Field
Research Program
PoF Topic
Subtopic